 Jaehoon Lee
2024.05.03
Jaehoon Lee
2024.05.03
시계열 Foundation 모델 최신 연구 동향
인공지능 분야에서 시계열(Time Series) 데이터는 일반적으로 주식, 센서 데이터와 같이 시간 축을 갖는 테이블 형태의 데이터(Tabular Data)를 의미합니다. 이러한 시계열 데이터는 다양한 분야에서 활용되고 있습니다. 날씨 데이터, 공장 센서 데이터, 금융 데이터 등이 대표적인 예시입니다. 우리 삶에 밀접한 데이터가 많은 만큼, 시계열 문제를 해결하는 것은 중요한 의미를 갖습니다. 미래의 날씨를, 공장 기계 고장 여부를, 금융의 변화를 조금이라도 미리 예측할 수 있다면, 우리는 불확실한 미래에 더욱 효과적으로 대응할 수 있을 것입니다. 그에 따라 AI 분야에서도 시계열 문제를 해결하기 위해 다양한 노력들이 이뤄지고 있습니다. 이번 글에서는 그 중 최근 많은 주목을 받고 있는 시계열 Foundation 모델에 관한 노력들을 공유하고자 합니다.
1. 시계열 Foundation 모델의 등장
Foundation 모델은 거대한 데이터로 사전 학습(Pre-trained)하여 다양한 문제를 해결할 수 있는 가능성을 가진 모델을 의미합니다.[1] Foundation 모델의 중요한 특징은 특정 문제에만 특화된 모델이 아니라 일반화된(Generalized) 모델이라는 점입니다. 자연어, 비전 등의 도메인에서 연구된 여러 Foundation 모델들이 다양한 Task에서 최고의 성능을 보이는 등, 그 가능성을 보이고 있습니다. 그에 따라, 최근 시계열에서도 Foundation 모델을 만들기 위해 많은 노력들이 이뤄지고 있습니다.
2. 시계열 Foundation 모델의 분류
최근까지의 시계열 Foundation 모델 연구를 살펴보면, 크게 거대 언어 모델(Large Language Model, LLM)을 활용하는 방법론과, 시계열을 위한 자체 거대 모델을 고안하는 방법론으로 분류할 수 있습니다. (그림 1) 거대 언어 모델 기반의 방법론은 어떻게 거대 언어 모델을 활용하는지에 따라 1) Without Adaptation, 2) Adapt LLM, 3) Adapt to LLM 3가지로 분류됩니다. 그리고 자체 언어 모델을 구축하려는 연구에서는 거대 시계열 데이터를 수집하기 위한 노력과, 다양한 시계열 데이터를 학습하기 위한 하나의 통일된 모델을 만들려는 노력이 존재합니다.
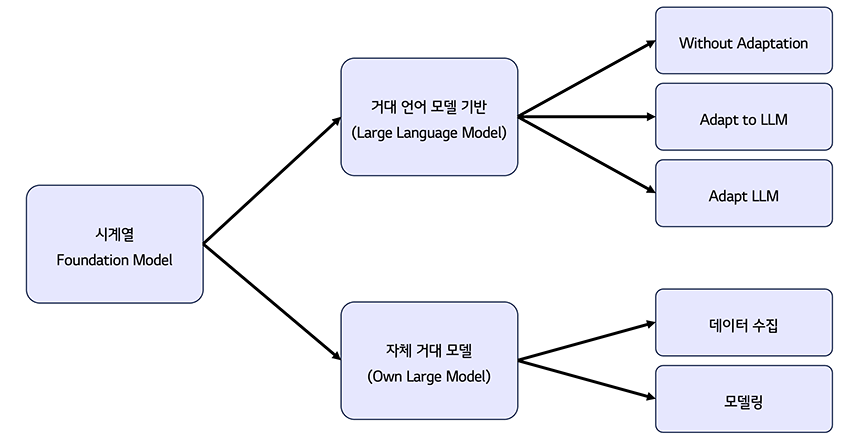
그림 1. 시계열 Foundation 모델 분류
2-1. 거대 언어 모델 기반 시계열 Foundation 모델
이 방법론은 기본적으로 거대 언어 모델로부터 일반화된 능력을 얻어, 시계열 Foundation 모델을 구축하고자 합니다. 어떻게 거대 언어 모델을 활용하는지에 따라 다음과 같이 세부적으로 나누어질 수 있습니다.
1) Without Adaptation. 이 방법론에서는 거대 언어 모델이 어느정도 시계열 도메인의 지식을 다양한 자연어 데이터로부터 습득했다고 가정합니다. 그렇기 때문에, 거대 언어 모델이 시계열 도메인에 익숙해지는(Adapt) 과정을 거치지 않거나 최소화합니다. 이 방법론에서는 주로 시계열 문제에 대해 어떻게 좋은 프롬프트(Prompt)를 작성할 것인지를 고민합니다.
예를 들어, PrompCast는 그림 2와 같이 인풋 아웃풋 텍스트를 설계해 시계열 문제를 해결할 수 있도록 했습니다.[2] 하지만, 한 논문에서는 이러한 방식으로 Prompt를 설계하면 큰 문제가 발생할 수 있다고 지적합니다.[3] 대표적인 이유로 숫자에 대한 불규칙적인 토큰화를 제시합니다. 예를 들어, 480을 토큰화 할 때는 480인 하나의 토큰으로 만들어지는 반면에, 481은 48과 1로 2개의 토큰으로 만들어진다고 합니다. 이러한 문제는 거대 언어 모델이 숫자를 잘 이해할 수 있는가에 대한 의문을 남깁니다.
그래서 LLM-Time에서는 이러한 문제를 해결하기 위해, 각 숫자(Digit)을 하나의 토큰으로 표현하는 등의 시도을 통해 시계열 문제를 거대 언어 모델이 잘 이해할 수 있도록 개선했습니다.[4] 이 연구에서 가장 흥미로운 점은, 거대 언어 모델이 Fine-tuning과 같은 추가적인 학습 과정을 전혀 거치지 않았음에도, 시계열 예측에서 좋은 성능을 보였다는 점입니다. 해당 연구는 이러한 현상에 대해, 거대 언어 모델은 간단한 패턴을 파악할 수 있는 능력이 있고, 시계열 문제를 풀 때 복잡한 패턴보다 간단한 패턴에 집중하는 것이 좋은 성능으로 이어지기 때문이라고 설명합니다.
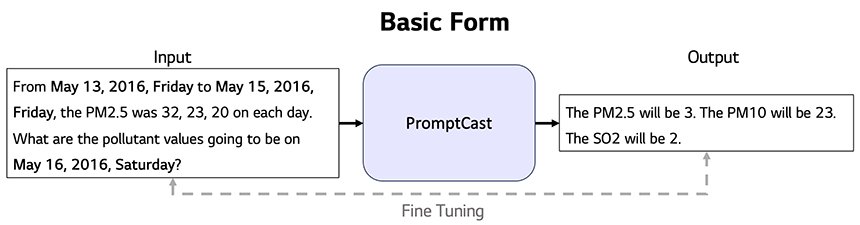
그림 2. PromptCast 구조[2]
2) Adapt LLM. Without Adaptation 방법론과 달리 이 방법론에서는 기본적으로 거대 언어 모델이 시계열 도메인에 대해서 익숙하지 않은 부분이 존재하고 익숙해지는(Adapt) 과정이 필요함을 강조합니다. 이 방법론의 모델은 보통 그림 3과 같은 형태를 가지고 있습니다. 거대 언어 모델이 중심 모델로 자리하고, 앞뒤로 시계열 데이터와 거대 언어 모델을 연결해 주는 Adaptation Layer가 존재합니다. 거대 언어모델의 전체 혹은 일부와 주변 Adaptation Layer를 시계열 데이터에 Fine-tuning함으로써, 거대 언어 모델이 시계열 데이터에 보다 익숙해질 수 있도록 합니다.
이 방법론의 연구에서 중요한 질문은 ‘Adaptation Layer를 어떻게 설계할 것인가?’, 그리고 ‘거대 언어모델을 어떻게 Fine-tuning할 것인가?’입니다. OFA는 그림 4에서처럼 Patching을 이용해서 시계열을 토큰화하고 거대 언어 모델 앞 뒤로 Linear Layer를 두어 모델을 설계했습니다.[5] 또한, 거대 언어 모델의 전체 파라미터를 학습시키는 것이 아니라, 일부만 학습시킴으로써 성능을 향상시켰습니다. 이 논문에서는 시계열 문제마다 Output Layer를 다르게 두어, 다양한 시계열 문제에 확장될 수 있음을 보이고 있습니다. 예를 들어, Output Layer가 단순한 Linear 형태이면 회귀 문제를 해결하기 위한 모델이 되고, Output Layer가 Linear와 Softmax가 결합된 형태이면 분류 문제를 위한 모델이 됩니다.
이 연구를 바탕으로 TEMPO에서는 시계열 분해를 바탕으로 한 Patching과 LoRA (Low-Rank Adaptaion)을 활용해 더욱 성능을 끌어올렸습니다.[6] 또한, LLM4TS 연구에서는 Fine-tuning의 과정을 또 더 세분화하는 방법을 제안했습니다.[7] 우선 전반적인 시계열 데이터에 익숙해지기 위한 학습을 진행한 후 예측과 같은 특정 시계열 문제에 초점을 맞춰 학습하는 과정을 제안했습니다.
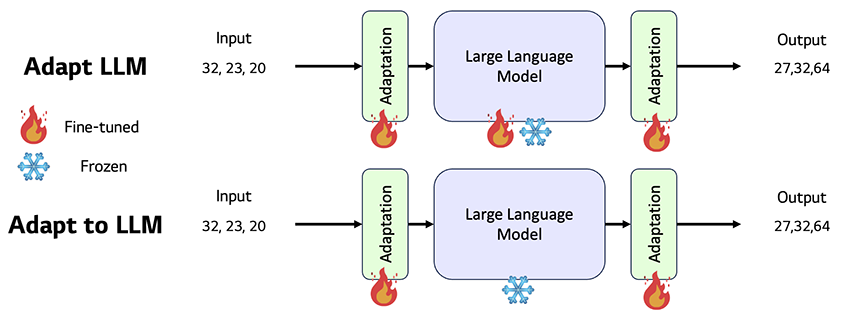
그림 3. 'Adapt LLM'과 'Adapt to LLM' 방법론의 모델 구조 차이
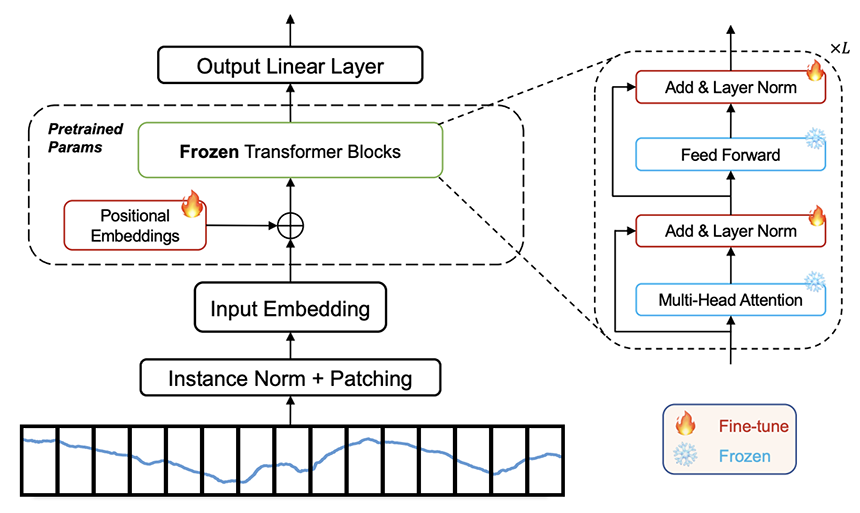
그림 4. OFA 구조[5]
3) Adapt to LLM. 이 방법론은 앞선 두 방법론의 중간 정도라고 생각할 수 있습니다. Without Adaptation은 거대 언어 모델이 시계열 도메인에 대한 지식이 어느정도 있음을 가정하는 반면, Adapt LLM은 거대 언어 모델이 시계열 도메인에 대한 지식이 부족하다는 것을 전제로 하고 있습니다. 이들과 달리 이 방법론은 거대 언어 모델이 ‘텍스트로 변환된 시계열 도메인에 대한 지식’이 있다는 것을 바탕으로 합니다. 다시 말해, 거대 언어모델이 시계열 도메인을 이해할 수 있지만, 텍스트로 변환되었을 경우로 한정한 것입니다.
그렇기 때문에 이 방법론의 연구에서 가장 중요한 질문은 “시계열 데이터를 어떻게 텍스트로 잘 변환할 수 있을까?”입니다. 그림 3은 해당 방법론에서 일반적으로 어떻게 모델이 설계되는지 나타냅니다. Adapt LLM과 상당히 유사하지만 거대 언어모델을 전혀 학습시키지 않는다는 점에서 명확한 차이가 존재합니다. 또한, 그림 5는 직관적으로 어떠한 방식으로 이 방법론이 작동하는지를 보여줍니다. 양쪽의 Fine-tuning된 Adaptation Layer가 시계열과 텍스트를 상호 변화시키고, 중간의 거대 언어모델이 텍스트로 변환된 시계열 데이터를 바탕으로 특정 Task를 수행하게 됩니다. 대표적으로 Time-LLM 연구에서는 시계열을 텍스트로 변환하는 과정을 명확하게 하기 위해 Cross Attention 메커니즘을 활용합니다.[8] 인풋 시계열 데이터를 쿼리로 텍스트의 여러 단어를 키, 밸류로 사용해, 시계열 데이터를 텍스트로 매핑시킵니다.
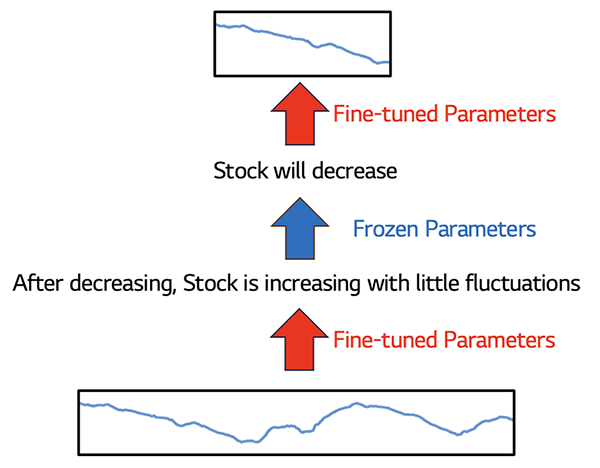
그림 5. 'Adapt to LLM' 방법론의 직관적 시각화
2-2. 자체 모델 기반 시계열 Foundation 모델
Foundation 모델로서 일반화 능력을 갖기 위해, 주로 거대 언어 모델에게 의존했던 앞선 방법론과 달리, 해당 방법론은 시계열을 위한 자체 거대 모델을 구축하는 것이 목표입니다. 그래서 해당 방법론의 연구는 일반화된 능력을 갖출 수 있을 만큼 충분한 데이터를 수집하는 것을 중요하게 여깁니다. 수집된 다양한 시계열 데이터 사이에는 관찰 주기(Frequency) 혹은 시계열 도메인의 차이와 같은 다양한 이질성(Heterogeneity)이 존재하는데, 거대하면서 이질적인 데이터를 수용할 수 있는 하나의 일반화된 모델을 구축하는 방향으로도 다양한 연구가 진행 중입니다.
해당 방법론의 대표적인 연구로 TimeGPT[9], TimesFM[10], Moirai[11] 등이 있습니다. 그림 6이 이 모델들의 특징을 잘 정리해서 보여줍니다. 세 방법론 모두 백억 개 이상의 거대한 데이터를 수집하고, 수집된 모든 데이터를 이용해 모델을 학습함으로써 Foundation 모델을 구축하고자 했습니다.
그 중, TimesFM은 검색 빈도의 추이를 보여주는 Google Trend 데이터, Wikimedia 페이지 들의 View수를 보여주는 Wiki Pageview 데이터, 그리고 간단한 시계열 패턴을 갖는 합성 데이터를 만들어 활용합니다. 다른 연구와 달리, 이 연구는 더 쉽게 구할 수 있는 데이터를 활용해 큰 데이터 셋을 구축하고 모델을 학습시켰다는 점에서 의미가 큰 연구입니다.
일반화된 모델 구축과 관련해, 해당 방법론의 연구 대부분이 1억개 이상의 파라미터를 갖는 Transformer 계열의 모델을 채택했습니다. TimeGPT처럼 Encoder-Decoder 계열의 모델을 사용하는 경우가 있고, TimesFM과 Moirai처럼 Decoder-Only 계열의 모델을 사용하는 경우가 있습니다. 시계열에서 일반화된 모델을 구축하기 위해, Moirai에서는 관찰 주기(Frequency)별로 다른 Patch 크기를 사용하고, 변수를 랜덤하게 샘플링해서 다변수 시계열 문제를 해결합니다.
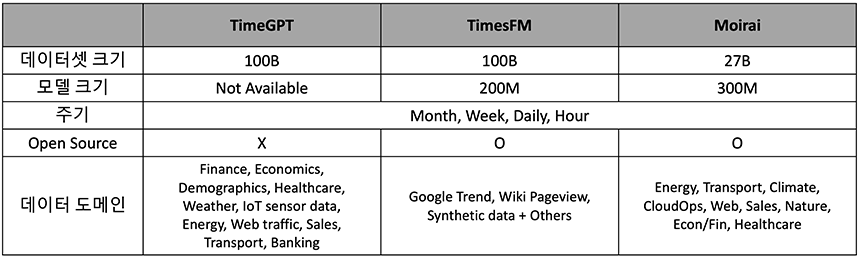
그림 6. TimeGPT[9], TimesFM[10], Moirai[11] 특징
3. LG AI연구원의 향후 계획
앞서 소개해 드렸듯이, 시계열을 위한 Foundation 모델이 최근 활발하게 연구되고 있습니다. 하지만 해당 연구가 오래 이뤄지지 않은 만큼, 많은 부분에서의 고민과 개선이 더욱 필요한 상황입니다. LG AI연구원에서는 기존의 연구가 갖고 있는 근본적인 문제를 발견하고 이를 해결하기 위해 노력하고 있습니다.
LG AI연구원의 Advanced Machine Learning(AML) Lab에서는 대부분의 시계열 Foundation 모델이 다변수(Multivariate)를 고려하지 못하는 단변수(Univariate) 모델이라는 한계를 발견하고 이를 해결하기 위한 방법을 탐구 중입니다. 세상의 모든 시계열은 (그 정도는 경우마다 다를 수 있지만) 모두 서로 연결됐다고 할 수 있습니다. 예를 들어, 기온이 올라가면 에어컨의 수요가 늘어나고 이는 특정 회사의 주가에 영향을 줄 수 있습니다. 일반적인 시계열 모델을 구축하고자 하는 Foundation 모델 연구는, 이렇게 모든 시계열이 서로 연관됐다는 가정을 바탕으로 탄생했다고 볼 수 있습니다.
따라서 기존에 있던 기술을 바탕으로 다변수 Foundation 모델을 구축하기 위해서는 거의 무한대에 가까운 시계열을 한꺼번에 고려해야 합니다. 하지만 이는 현재의 기술로서는 거의 불가능하기 때문에 대부분의 기존 모델들은 한 번에 하나의 시계열만 고려하는 단변수 기반의 방법론을 구축했습니다.
반면, LG AI연구원 AML Lab에서는 단변수 모델이 다변수 모델에 비해 갖는 모델 능력(Capacity) 측면의 한계를 확인하고, 시계열 개수가 무한대에 가까운 상황에서 다변수 모델로 나아가기 위한 랜덤 샘플링 방법을 제안했습니다. 무한대에 가까운 모든 시계열을 한꺼번에 고려하는 것이 아니라, 그 중 몇 개만을 랜덤하게 샘플링해서 학습하더라도 전체를 가지고 학습한 효과를 낼 수 있다는 가능성을 확인했습니다.
LG AI연구원에서는 이러한 문제 이외에도 시계열 Foundation 모델에서 해결해야할 다른 중요한 근본적인 문제들을 발견하고 이를 바탕으로 발전된 시계열 Foundation 모델을 만들기 위한 연구를 이어 나갈 예정입니다.
- 참고
- [1] R. Bommasani et al., “On the Opportunities and Risks of Foundation Models.” arXiv, Jul. 12, 2022. doi: 10.48550/arXiv.2108.07258.
[2] H. Xue and F. D. Salim, “PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting,” arXiv.org. Accessed: Jan. 08, 2024. [Online]. Available: https://arxiv.org/abs/2210.08964v5
[3] D. Spathis and F. Kawsar, “The first step is the hardest: Pitfalls of Representing and Tokenizing Temporal Data for Large Language Models,” arXiv.org. Accessed: Jan. 08, 2024. [Online]. Available: https://arxiv.org/abs/2309.06236v1
[4] N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “Large Language Models Are Zero-Shot Time Series Forecasters,” arXiv.org. Accessed: Jan. 08, 2024. [Online]. Available: https://arxiv.org/abs/2310.07820v1
[5] T. Zhou, P. Niu, X. Wang, L. Sun, and R. Jin, “One Fits All:Power General Time Series Analysis by Pretrained LM,” arXiv.org. Accessed: Jan. 08, 2024. [Online]. Available: https://arxiv.org/abs/2302.11939v6
[6] D. Cao et al., “TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting,” arXiv.org. Accessed: Jan. 08, 2024. [Online]. Available: https://arxiv.org/abs/2310.04948v2
[7] C. Chang, W.-Y. Wang, W.-C. Peng, and T.-F. Chen, “LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters,” arXiv.org. Accessed: Jan. 08, 2024. [Online]. Available: https://arxiv.org/abs/2308.08469v4
[8] M. Jin et al., “TIME-LLM: TIME SERIES FORECASTING BY REPRO- GRAMMING LARGE LANGUAGE MODELS”.
[9] A. Garza and M. Mergenthaler-Canseco, “TimeGPT-1.” arXiv, Oct. 05, 2023. Accessed: Feb. 14, 2024. [Online]. Available: http://arxiv.org/abs/2310.03589
[10] A. Das, W. Kong, R. Sen, and Y. Zhou, “A decoder-only foundation model for time-series forecasting.” arXiv, Feb. 04, 2024. Accessed: Feb. 13, 2024. [Online]. Available: http://arxiv.org/abs/2310.10688
[11] G. Woo, C. Liu, A. Kumar, C. Xiong, S. Savarese, and D. Sahoo, “Unified Training of Universal Time Series Forecasting Transformers.” arXiv, Feb. 04, 2024. Accessed: Feb. 13, 2024. [Online]. Available: http://arxiv.org/abs/2402.02592



